데이터 구조(1)
연결 리스트 ( linked List )
리스트는 데이터 구조의 하나로 데이터를 일직선으로 나열한 구조를 가진다 데이터 추가나 제거는 쉽지만 데이터 탐색은 오래 걸린다
이런 리스트가 있으면 각각의 화살표는 포인터가 되고 다음 데이터의 위치를 가리킨다(연속적이지 않아도 되는 이유)
메모리상에 연속적으로 위치하지 않아도 된다
연결 리스트 내에 다음 노드의 메모리 주소도 저장해야 한다 (서로 인접하지 않은 셀을 노드라고함)
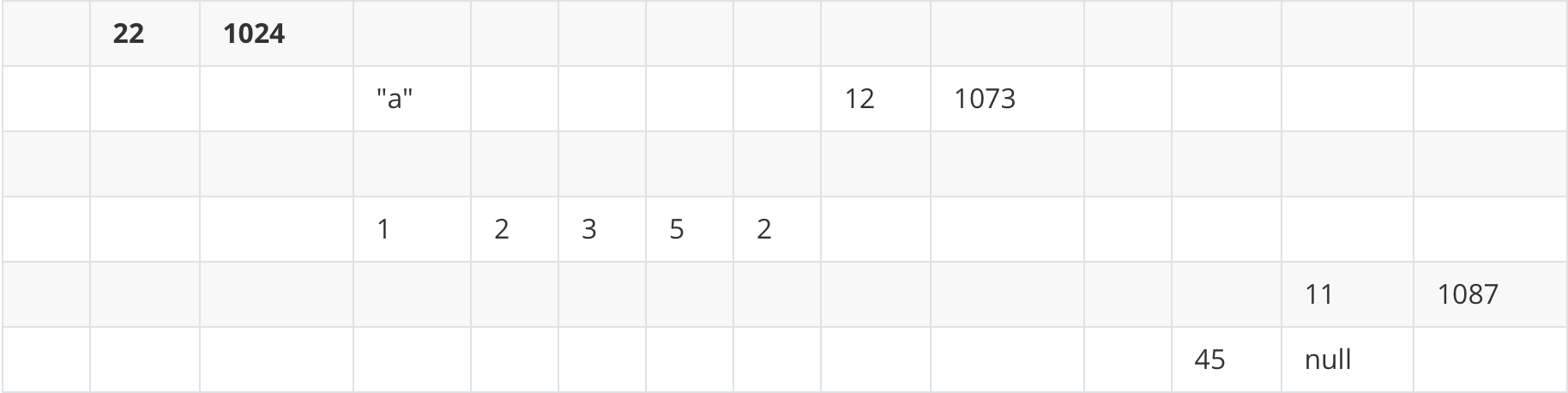
메모리속
연결 리스트는 연속되지 않은 셀에 저장될 수 있어서 22,12,11,45와 같이 저장될 수 있다
안의 원하는 데이터를 찾으려면 처음부터 확인해야 한다 -> 탐색 시간이 느림 (처음 주소에서 포인터를 따라가야해서)
데이터 추가나 삭제는 포인터가 가리키는 위치만 변경하면 된다 -> 데이터 추가나 삭제는 빠르다
연결 리스트 탐색 시간 O(n) 선형 탐색
연결 리스트 추가 제거 시간 O(n) 앞에서 하면 O(1)
배열 ( Array )
배열은 데이터를 1열로 나열한 것 리스트와 달리 메모리의 연속적으로 저장된다
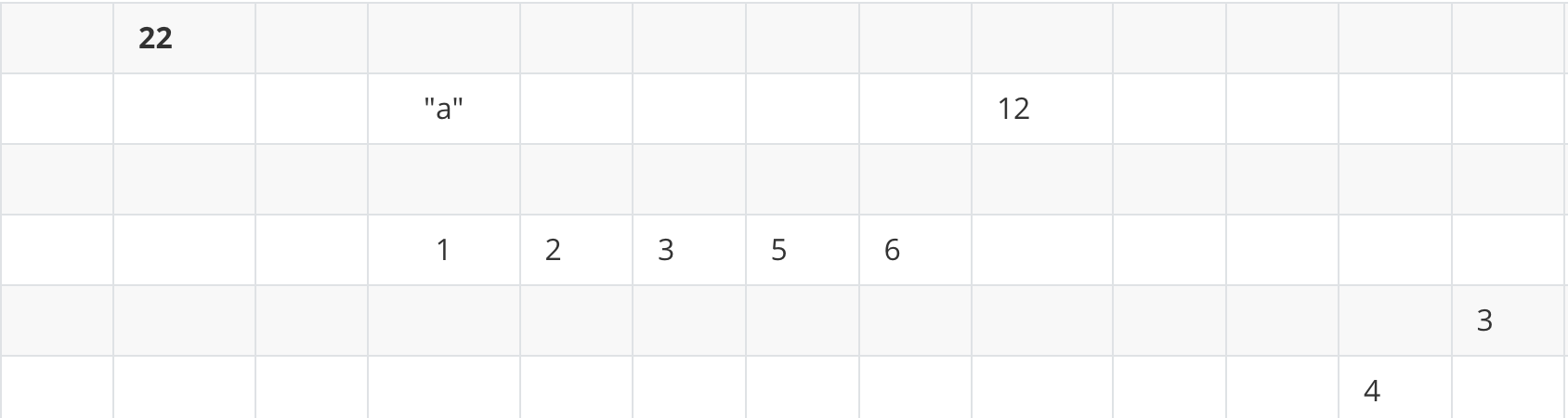
위 한칸 한칸이 메모리 저장 공간일때 연속된 빈 셀에 저장된다 -> 위 1,2,3,5,6과 같이
그러므로 데이터 추가 삭제는 느리고 탐색은 리스트에 비해 빠르다
a는 배열의 이름이고 [] 안의 숫자는 배열의 몇 번째 요소인지를 나타낸다
배열은 연속된 메모리에 저장되어 메모리 주소로 계산 가능하다 -> 임의 점근 가능 -> 접근시간 빠름
(프로그램은 배열이 어떤 메모리 주소로부터 시작하는지 알고 있고 인덱스도 알아 바로 접근 가능)
데이터를 중간 추가해야 하는 경우 그 위치 뒤로 모든 데이터를 한 칸씩 뒤로 옮기고 넣어야 한다 -> 추가시간 느림
제거도 그 위치 데이터 삭제 후 뒤에 있는 데이터를 앞으로 당겨야 한다
배열 탐색 시간 O(1) 임의 접근
배열 추가 제거 시간 O(n) 끝에서 하면 O(1)
| 접근 | 추가 | 삭제 | |
|---|---|---|---|
| 리스트 | 느림 | 빠름 | 빠름 |
| 배열 | 빠름 | 느림 | 느림 |
스택( Stack )
데이터를 1열로 나열하지만 마치 서류를 쌓아 놓은 것처럼 먼저 온 것이 아래로 가고 최신 것이 위로 오게 된다
나중에 온 것이 먼저 나가는 구조
후입선출 구조(Last In First Out) LIFO라고 한다
위 스택이 있을 때 red를 추가하는 것을 push라고 한다
스택에서 데이터를 꺼내는 경우를 pop이라고 하며 제일 최신의 데이터가 pop 된다
데이터 추가나 삭제는 단방향으로만 가능하다
항상 최신 데이터만 접근해야 하는 경우에 사용된다
ex) 괄호의 대응 관계 찾기
큐( Queue )
데이터를 1열로 나열한다 스택과 비슷하지만 추가와 제거가 반대 축이다
줄을 서는 것과 같다 먼저 온 것이 먼저 나가고 나중에 온 것이 나중에 나간다
선입선출 구조(First In First Out) FIFO
데이터 추가를 enqueue라고 하고 blue를 인큐하면
데이터 꺼내는 경우 dequeue라고 하고 디큐하면
앞에 있는 green이 꺼내지고 큐는 red, blue로 바뀐다
해시테이블 (Hash Table)
해시함수와 함께 사용되고 검색을 효율적으로 하기 위한 데이터 구조이다
키(key)와 값(value)를 함께 저장한다
| Key | Value |
|---|---|
| Nick | M |
| Dan | M |
| John | M |
| Bob | M |
| Sera | F |
| Nell | F |
만약 배열에서 sera의 성별을 찾으려면 nick부터 sera까지 전부 선형 탐색을 해야 성별을 찾을 수 있다
해시 테이블로 저장할 경우
먼저 배열을 하나 만든다 배열의 크기는 임의로 결정
- 배열의 크기가 작으면 충돌이 많아지고 선형 탐색의 빈도가 높아진다
- 배열의 크기가 너무 크면 메모리 낭비
크기가 3인 배열로 결정하면 a[0] a[1] a[2]로 빈 배열을 만든다
key 값을 해시함수를 통해 해시값을 계산한다
나온 해시값을 전체 배열의 크기로 나누고 나머지에 해당하는 배열 번호에 넣는다
Nick -> 해시함수 -> 2341(해시값) -> 2341 배열개수 mod연산 -> 나머지에 해당하는 배열 상자에 넣는다
| a[0] | a[1] | a[2] |
|---|---|---|
| Nick M | Dan M | John M |
| Bob M | Nell F | |
| Sera F |
위와 같이 계산을 반복하고 배열상자에 값이 이미 있으면 이를 충돌이라 하고 리스트 구조로 데이터를 연결한다 위에서는 Nick, Bob와 Sera가 충동을 일으켰는데 a[0]에 데이터들이 리스트로 이어져있다
충돌이 일어난 경우
위에 방법처럼 리스트로 연결하는 것은 연쇄법(chaining)
개방 주소법 다음 후보가 될 주소를 찾아 저장한다 찾는 방법으로는 여러 개의 해시함수를 이용하거나 선형 탐사를 이용 가능하다
데이터 검색 방법
key 값을 받아 해시함수에 넣고 mod 계산을 통해 배열에서의 위치를 알아낸다 배열에는 리스트로 저장되어 있을 수 있으므로 리스트에서 선형 탐색해서 찾게 된다
처음부터 선형 탐색을 해서 찾는 것보다 데이터 수가 줄어서 더 빠르게 데이터 검색을 할 수 있다